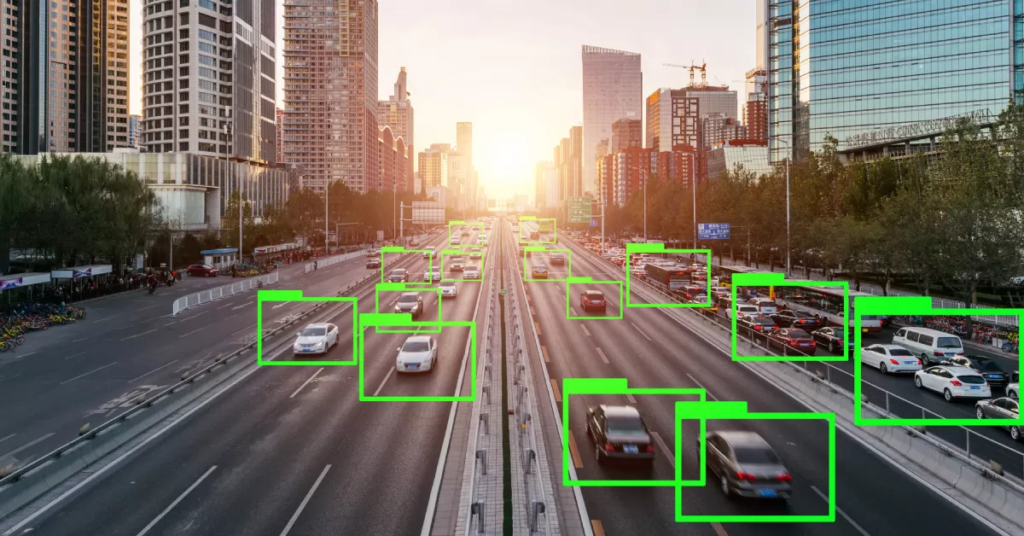
Today’s artificial intelligence (AI) era has made data annotation a crucial part of creating reliable machine learning models. This guide aims to offer a thorough understanding of data annotation, its significance in AI projects, the distinction between data labeling and annotation, the method of annotating data for AI, the difference between highly sought-after labeling experts and businesses offering data annotation services, and a summary of the various types of data annotation used in computer vision and natural language processing (NLP).
What Data Annotation Is & Why It Matters:
In order for machines to comprehend and analyze the data, certain data sets must be given meaningful labels or tags. By giving the data required to identify patterns and make precise predictions, it plays a critical part in training machine learning algorithms. The highest possible performance and desired results from AI algorithms are guaranteed by properly labeled data.
What Distinguishes Data Labeling from Annotation?
In the context of machine learning, the terms “data annotation” and “data labeling” are frequently used interchangeably. Both phrases describe the action of labeling data sets. Data annotation includes a wider range of tasks, such as semantic segmentation, 2D boxes, and optical character recognition (NLP), whereas data labeling largely concentrates on giving descriptive labels to data. These annotations enable more complex analysis by assisting machines in understanding various forms of data.
What is the procedure for annotating data for AI?
In order to train machine learning algorithms and incorporate artificial intelligence into apps, devices, or production lines, the process of annotating data for AI entails a number of processes.
Data Collection: Gathering the necessary data is the initial step in the procedure. Depending on the particular AI task you are using, the data format may change. For instance, if you’re developing an image recognition system, you’ll need to compile a sizable number of images of the items the system will be able to identify. Similar to this, in order to automate the conversion into editable text files when using optical character recognition (OCR), you need a sizable collection of handwritten text.
Determining amount of data: There is no clear-cut solution to the frequently asked question of the quantity of data is required. In general, more data is preferable since a bigger dataset makes it possible to use artificial intelligence techniques, sometimes known as big data, to find hidden patterns. For instance, a web-based retailer can use a ton of data to offer people individualized recommendations based on their tastes and shared characteristics with other users.
Problem of overfitting: A machine learning model that has been overfitted, also known as over trained, performs poorly on new, untrained data because it has become overly specialized in the training data. While having a large amount of data reduces overfitting, it’s still crucial to maintain equilibrium. Concentrate on the quality and usefulness of the data rather than stressing about the volume of data. For machine learning algorithms to be trained successfully, it is essential to gather the appropriate data that accurately reflects the issue area.
Annotation criteria: It’s important to think about the criteria for annotation rather than focusing solely on the volume of data. Data annotation is a time-consuming and expensive process, thus it’s crucial to make sure the annotations are accurate and of high quality. The
knowledge that machine learning algorithms need to identify patterns and make precise predictions is provided by well-annotated data. Annotation criteria cover things like consistency, accuracy, and relevance to the current AI work.
In-Demand Annotation Professionals vs. Data Labeling Providers:
Organizations must decide whether to work with companies that specialize in data annotation services or hire highly sought-after labeling experts when starting an AI project.
Data annotators are experienced individuals in high demand who specialize in labeling. They are very knowledgeable about particular annotation chores and may offer specialized solutions to fulfill project needs. Hiring internal specialists that are participating in the project directly and are able to adjust to changing requirements can provide you more control over the annotating process.
On the other hand, businesses that offer data annotation services have a number of benefits. These businesses have devoted teams of knowledgeable annotators who are skilled in a variety of tools and procedures. They can easily manage large-scale annotation projects and offer quicker turnaround times. Businesses can also access a larger spectrum of annotation expertise, save time, and lower costs by outsourcing data annotation to specialist organizations.
The choice between in-demand labeling specialists and data annotation firms ultimately comes down to the particular requirements and available resources of the organization. Both approaches have advantages and can help AI projects be completed successfully by annotating data in a precise and trustworthy manner.
Annotation in Natural language processing (NLP) and computer vision (CV):
Computer vision (CV) and natural language processing (NLP) activities for data annotation can be widely characterized. Image categorization, semantic segmentation, 2D boxes, 3D cuboids, polygonal annotation, and key point annotation are just a few of the image-related data features that are the focus of CV. NLP, on the other hand, works with text-based data and encompasses activities like text categorization, named entity recognition (NER), optical character recognition (OCR), and intent/sentiment analysis.
Annotation in Computer Vison:
Various annotation tasks essential for training AI models are covered by computer vision, including:
Polygonal Annotation: Using polygonal outlines, complex-shaped objects are marked, providing thorough details that aid in item identification.
Image Categorization: Machine learning algorithms are taught to categorize photos into specified categories, allowing for the recognition of objects or features in the images.
2D boxes: Bounding boxes are drawn around objects in images as annotations, providing spatial information and assisting with object detection and tracking.
Semantic Segmentation: Machines are trained to link each pixel of an image with a particular class of objects using semantic segmentation, which enables accurate object recognition and comprehension.
Keypoint Annotation: To facilitate accurate localization and tracking, certain locations of interest, such as face landmarks or joint positions, are labeled.
3D Cuboids: This sort of annotation involves drawing 3D bounding boxes around objects in photos, which is essential for activities like object manipulation and autonomous driving.
Annotation in NLP:
To extract meaning from text-based data, NLP uses a variety of annotation tasks:
Named Entity Recognition (NER): Named entities are recognized and marked in text to help with information extraction and analysis. Examples of named entities are names, places, organizations, and dates.
Intent/Sentiment Analysis: Text is annotated depending on the explicit intent or attitude, allowing robots to comprehend the underlying meaning or emotional undertone.
Text classification: Predefined categories are used to label text documents, making it possible for computers to recognize and classify text according to its content.
Optical Character Recognition (OCR): OCR converts handwritten or printed text contained in images into machine-readable text, enabling textual data analysis and indexing.
A crucial component of the growth and development of artificial intelligence is data annotation. Data annotation makes it possible for robots to learn, analyze, and carry out complicated activities that were previously only capable of being done by humans. Annotated data gives machine learning algorithms the structure and context they need to find patterns, forecast outcomes accurately, and produce insightful information. In addition to assisting machines in understanding the world as we do, the process of data annotation also fosters advancements in a number of fields, including computer vision, natural language processing, and speech recognition. The potential for AI applications increases rapidly with the availability of vast and well-annotated datasets, spurring technological progress and revolutionizing businesses around the world.
Annotating data helps AI researchers bridge the gap between unstructured data and insightful conclusions. Annotation enables machine
learning algorithms to think like people by giving labeled data, leading to more accurate predictions and better decision-making. To ensure the success of their AI projects, enterprises must give high-quality annotation top priority, whether through internal expertise or cooperation with data annotation service providers.
In conclusion, utilizing the full potential of AI and developing intelligent systems that can disrupt several industries requires a thorough understanding of data annotation, its process, and its various types in computer vision and NLP.